Visualizing and Understanding Deep Texture Representations
Abstract
A number of recent approaches have used deep convolutional neural networks (CNNs) to build texture representations. Nevertheless, it is still unclear how these models represent texture and invariances to categorical variations. This work conducts a systematic evaluation of recent CNN-based texture descriptors for recognition and attempts to understand the nature of invariances captured by these representations. First we show that the recently proposed bilinear CNN model is an excellent general-purpose texture descriptor and compares favorably to other CNN-based descriptors on various texture and scene recognition benchmarks. The model is translationally invariant and obtains better accuracy on the ImageNet dataset without requiring spatial jittering of data compared to corresponding models trained with spatial jittering. Based on recent work of visualizing CNN, we propose a technique to visualize pre-images, providing a means for understanding categorical properties that are captured by these representations. Finally, we show preliminary results on how a unified parametric model of texture analysis and synthesis can be used for attribute-based image manipulation, e.g. to make an image more swirly, honeycombed, or knitted.
People
Approach
Our texture representation is based on our B-CNN model, which has shown excellent performance for fine-grained recognition. Our framework for texture synthesis, inversion, and attribute-based manipulation is based on the following optimization problem:
The first term penalizes the difference of B-CNN features from several layers of the CNN. This constraints the synthesized image to have similar texture to the source image (See also Gatys et al. [1]). The second term is the sum of negative log-likelihood of label Ĉ evaluated on B-CNN features obtained from several layers of convolutional output, which biases the synthesized output towards an attribute Ĉ. The third term is a natural image prior such as TVnorm (Also see Mahendran and Vedaldi [2]). The parameters αi, β and γ balance the tradeoff between these three terms. The optimization is solved using L-BFGS with gradient computed by back-propagation. Our features are based on very deep VGG 16-layer network (See Simonyan and Zisserman [3]) pre-trained on ImageNet dataset. We extract several layers of relu outputs to construct B-CNN featres. See more details in the paper.
Visualization of Attributes
We train linear classifiers of given attributes using B-CNN features on several dataset and visualize the pre-image of the attribute by solving the above optimization with αi=0, i.e. without source texture and no penalty on this term. The following shows some examples on Describable Texture Dataset (DTD), Flick Material Dataset (FMD) and MIT Indoor dataset. Click the images to see complete set of pre-images.
Describable Texture Datatset | |||||
 |
|||||
| braided | bubbly | fibrous | honeycombed | interlaced | meshed |
Flickr Material Dataset | |||||
 |
|||||
| foliage | glass | leather | plastic | water | wood |
MIT Indoor | |||||
 |
|||||
| bathroom | bookstore | bowling | closet | classroom | laundromat |
Texture with Attribute Manipulation
Given a source texture and a target attribute Ĉ, we can generate the texture containing the given attribute by solving the above optimization. Below are some examples (Click here to see more).
 |
 |
 |
 |
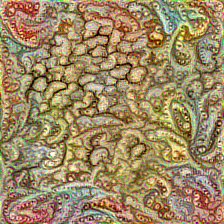 |
| source | dotted | fibrous | honeycombed | paisley |
Content with Attribute Manipulation
Unlike the texture manipulation, content manipulation preserves the spatial structure of the source image. The difference is that we use the convolutional features for each pixel without pooling to keep the overall structure of the image (See also Gatys et al. [4]). We modify the objective function to be:
Where the last term penalizes the reconstruction error of convolutional outputs between source and reconstructed images. The following are some examples (Click here to see more).
 |
 |
 |
 |
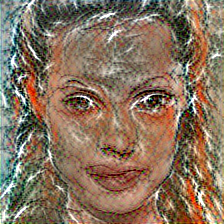 |
| input | interlaced | bumpy | veined | marbled |
Code
Please pull the code from our bitbucketThe models required to do the inversion for categories are provided for: dtd fmd mit_indoor
Paper
Tsung-Yu Lin, Subhransu Maji, "Visualizing and Understanding Deep Texture Representations"
[arXiv:1511.05197 cs.CV,
Nov 16, 2015]
References
- L. A. Gatys, A. S. Ecker, and M. Bethge, "Texture Synthesis Using Convolutional Neural Networks", NIPS 2015
- A. Mahendran and A. Vedaldi, "Understanding Deep Image Representations by Inverting Them", CVPR 2015
- K. Simonyan, A. Zisserman, "Very Deep Convolutional Networks for Large-Scale Image Recognition", arXiv 2014
- L. A. Gatys, A. S. Ecker, and M. Bethge, "A Neural Algorithm of Artistic Style", arXiv 2015
- Tsung-Yu Lin, A. RoyChowdhury, S. Maji, "Bilinear CNN models for Fine-Grained Visual Recognition", ICCV 2015