
Home
Research
Information
Clean Sets for Document-Specific Modeling
Overview
Optical character recognition (OCR) remains a difficult problem for noisy documents or documents not scanned at high resolution. Many current approaches rely on stored font models that are vulnerable to cases in which the document is noisy or is written in a font dissimilar to the stored fonts. We address these problems by learning character models directly from the document itself, rather than using pre-stored font models. This method has had some success in the past, but we are able to achieve substantial improvement in error reduction through a novel method for creating nearly error-free document-specific training data and building character appearance models from this data.
We use a third party OCR system (Tesseract1) to first obtain an initial translation of a document. Then, our algorithm selects a subset of these translated words which are believed to be correctly translated with high confidence, which we refer to as the clean set. We then use this clean set as training data to improve on the original OCR recognition. We also introduce a bound for including a mistaken translation into the clean set.
Code
Clean Set
- We show examples of words included in the clean set. Thick blue boxes indicate clean set words. Dashed red boxes indicate Tesseract’s confident word list. Thin green boxes indicate words in both lists. Despite being in Tesseract’s list of high confidence words, “timber” is misrecognized by Tesseract as “timhcr”. All other words in boxes were correctly translated by Tesseract.

Evaluation
- We show results comparing character error reduction rates using the clean set (SIFT Align Clean, shown in green) and Tesseract’s confident word list (SIFT Align Tess, shown in yellow) on a test set of 56 documents.
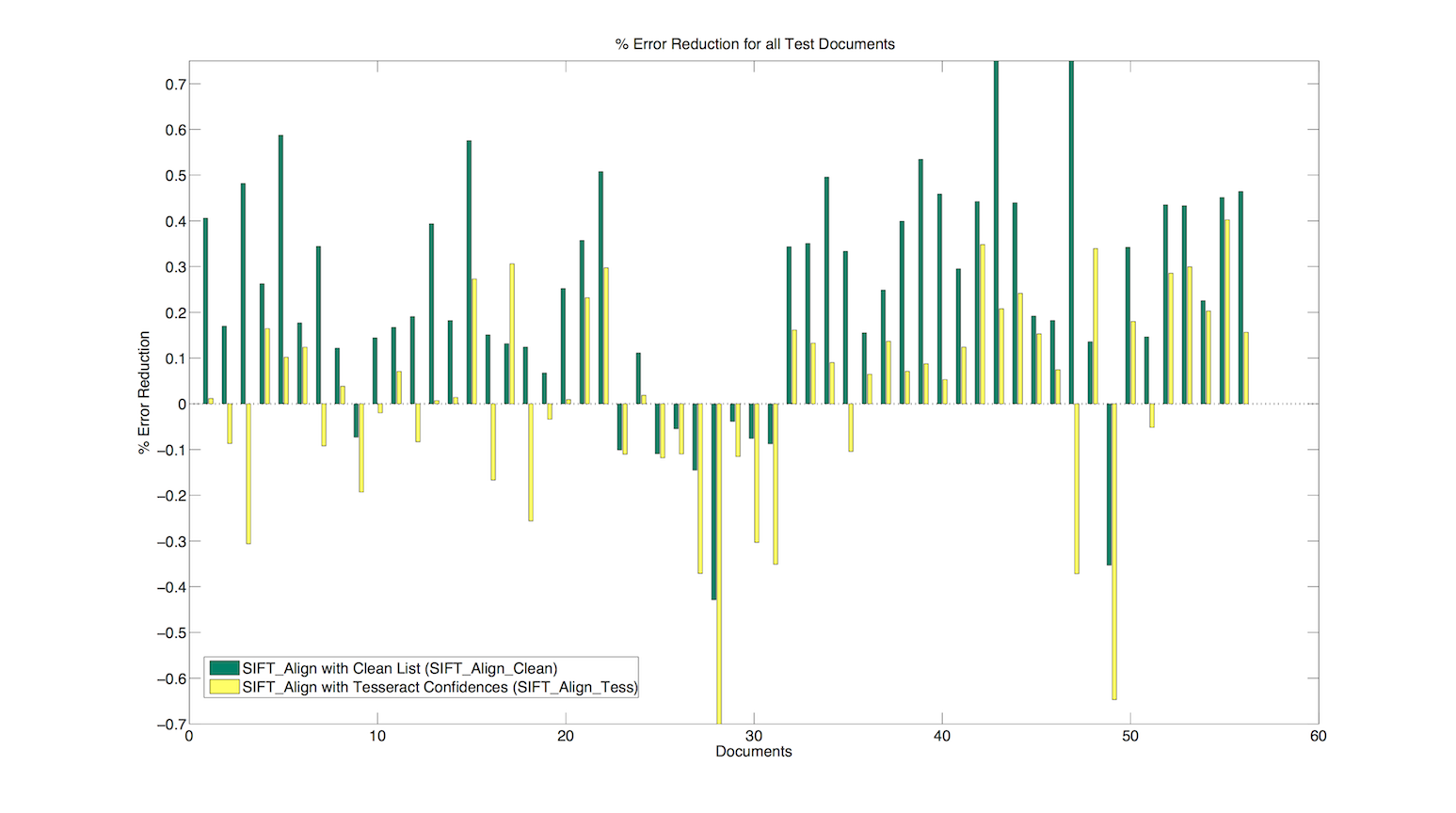
- SIFT Align Clean outperforms Sift Align Tess. Average error reduction for SIFT Align Clean is 34.1% compared to 9.5% for Sift Align Tess. SIFT Align Clean also reduces the character error in more documents than does Sift Align Tess.
Sample Results
- We show a sample of results from two documents. A thin green box indicates both Tesseract and SIFT Align correctly classified the character. A dashed red box indicates both systems misclassified the character, and a thick blue box indicates that SIFT Align classified the character correctly and Tesseract misclassified it. In this example, there are no cases shown where Tesseract correctly classified a character and SIFT Align misclassifies it.


Faculty
Graduate Students
References
-
Gary B. Huang, Andrew Kae, Carl Doersch, Erik Learned-Miller
Bounding the Probability of Error for High Precision Optical Character Recognition
Journal of Machine Learning Research (JMLR), 2012.
[pdf]. - Andrew Kae, Gary Huang, Carl Doersch, and Erik Learned-Miller
Improving State-of-the-Art OCR through High-Precision Document-Specific Modeling
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010.
[pdf] - Tesseract. [link]