
Home
Research
Information
GLOC Face Parts Labeling
Overview
The conditional random field (CRF) is a powerful tool for building models to label segments in images. They are particularly appropriate for modeling local interactions among labels for regions (e.g., superpixels). Complementary to this, the restricted Boltzmann machine (RBM) has been used to model global shapes produced by segmentation models. In this work, we present a new model that uses the combined power of these two types of networks to build a state-of-the-art labeler, and demonstrate its labeling performance for the parts of complex face images. Specifically, we address the problem of labeling the Labeled Faces in the Wild data set into hair, skin and background regions. The CRF is a good baseline labeler, but we show how an RBM can be added to the architecture to provide a global shape bias that complements the local modeling provided by the CRF. This hybrid model produces results that are both quantitatively and qualitatively better than the CRF alone. In addition to high quality segmentation results, we demonstrate that the hidden units in the RBM portion of our model can be interpreted as face attributes which have been learned without any attribute-specific training data.
On this page, we will distribute our code and models that we use the paper below.
Model
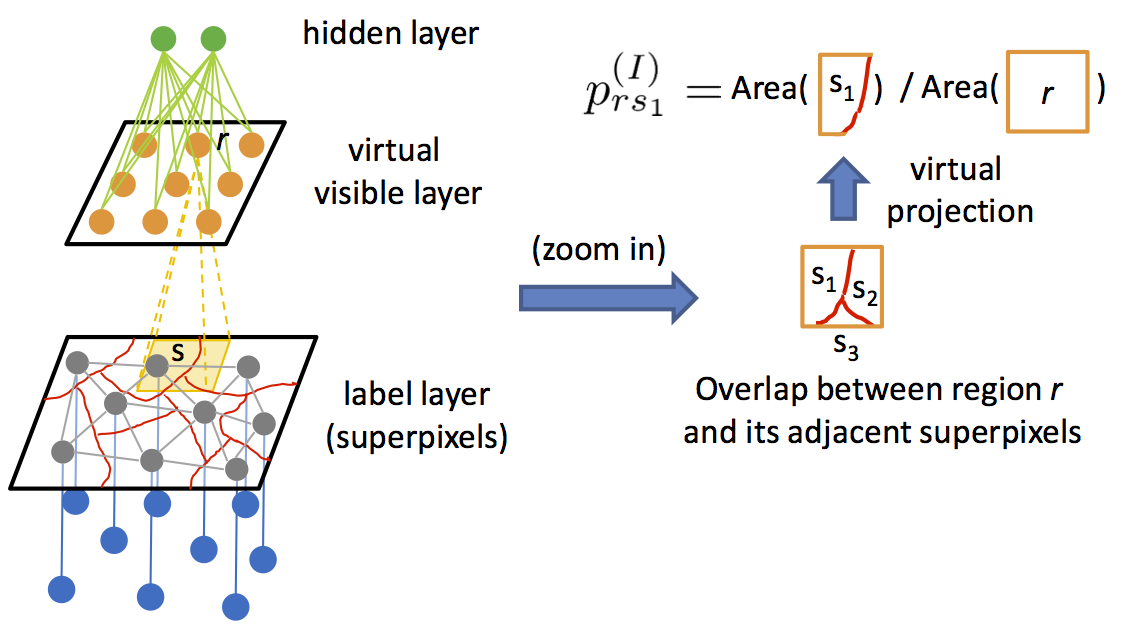
- The GLOC model is shown below. The top two layers can be thought of as an RBM with the (virtual) visible nodes and the hidden nodes. The bottom two layers correspond to a CRF. Please see the paper for details.
Data
- We used the Part Labels Database, which contains labelings of 2927 face images into Hair/Skin/Background labels.
Code
- gloc.zip (md5sum 1dc316d0fa1d2b003c7e8a804fb985e2)
Evaluation
- The labeling accuracies for each model are shown below. We report the superpixel-wise labeling accuracy in the second column, and the error reduction over the CRF in the third column.
| Method | Accuracy (Superpixel) | Error Reduction |
|---|---|---|
| CRF | 93.23% | - |
| Spatial CRF | 93.95% | 10.64% |
| CRBM | 94.10% | 12.85% |
| GLOC | 94.95% | 25.41% |
Sample Segmentations
We show some successful (and unsuccessful) labelings using our GLOC model. The columns correspond to- Original image which has been aligned to a canonical position using funneling
- CRF
- Spatial CRF
- GLOC
- Ground truth labeling
-
Successful Examples (Large Changes)

-
Successful Examples (Subtle Changes)
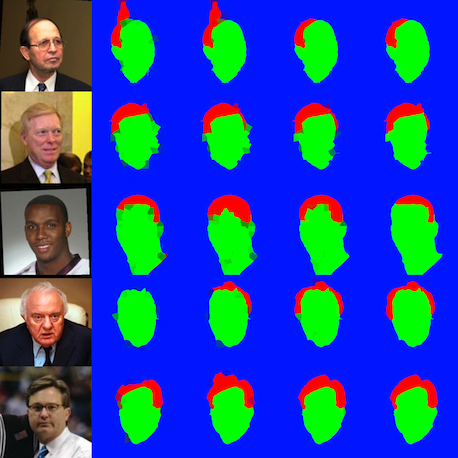
-
Unsuccessful Examples

Faculty
Graduate Students
References
- Andrew Kae*, Kihyuk Sohn*, Honglak Lee, and Erik Learned-Miller.
Augmenting CRFs with Boltzmann Machine Shape Priors for Image Labeling
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013.
*The first and second authors made equal contributions and should be considered co-first authors.
[pdf] - Andrew Kae, Ben Marlin, and Erik Learned-Miller.
The Shape-Time Random Field for Semantic Video Labeling
To appear at IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[pdf soon]